Here are some Lisp tidbits I'd thought I'd share, in case someone happens to be interested. Unless otherwise noted, I've placed all this Lisp code in the public domain.
On my system (a 400MHz Pentium II, running FreeBSD-3.2), the C version (compiled with cc -O3) took 0.35 seconds. My Lisp version took 0.84 seconds when compiled with CMUCL, and 1.37 seconds when compiled with Allegro CL 5.0.1. So, the CMUCL version takes 2.4 times as long as C, while ACL takes 3.86 times as long.
I don't know what this proves, but there it is. The lisp version is test-dct.lisp, and the C version is test-dct.c.
You can run the test by compiling and loading test-dct.lisp,
and then evaluating (test-dct *image*).
forward-dct! actually computes
something resembling a DCT
you'll also need to get the file
scale-dct.lisp. This contains code that will scale the results
of forward-dct! by appropriate factors, and yield the actual
DCT coefficients.
To check this out, do the following:
(load "test-dct.lisp") (load "scale-dct.lisp") (level-shift *image*) (forward-dct! *image*) (scale-block *image*)Now,
*image* will contain the DCT coefficients. Note that
the sample data is all from the example in the
introductory paper
by Gregory K. Wallace.
If anyone is really interested in this topic, I could probably find some time to make my notes on the DCT available on the net.
The Lisp DCT code could be further optimized in a couple of ways. The
2D input array could be replaced with a 1D array, as is done in the IJG
code. Also, aref is used to read the same value multiple
times. The value could be cached in a local variable rather than
re-read.
The code works on MCL, and in ACL 5.0.1 with CLX. It should probably work on other Common Lisps with CLX, too. (It has been verified that CMUCL and CLISP work, too.)
It's not optimized at all, but I think the code is pretty, and it's been fun to play with.
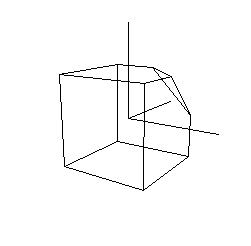
Sample commands:
(reset-transform)
(perspective 60 0.0001 1000)
(lookat (new-point 2 1 -3) (new-point 0 0 0) (new-point 0 1 0))
(draw-axes)
(draw-cubie)
Output:
A paper by Ross N. Williams, which describes CRC error detection algorithms in general, is available from his company's ftp site. I've kept a gzipped local copy of this paper as well.
The code runs pretty well in CMUCL, which (given appropriate declarations)
is able to deal with
32 bit integers directly. You certainly wouldn't want to call
update-crc for
every byte of input, because the return value has to be turned from
an unboxed (unsigned-byte 32) into
an integer (which will likely be a bignum).
I suppose it would also run well on machines with 32
bit fixnums. Otherwise, it will cons bignums like crazy.